189 8069 5689
众所周知,随着计算机、互联网、物联网、云计算等网络技术的风起云涌,网络上的信息呈爆炸式增长。毋庸置疑,互联网上的信息几乎囊括了社会、文化、政治、经济、娱乐等所有话题。使用传统数据收集机制(如问卷调查法、访谈法)进行捕获和采集数据,往往会受经费和地域范围所限,而且还会因其样本容量小、信度低等因素导致收集的数据往往与客观事实有所偏颇,有着较大的局限性。


网络爬虫通过统一资源定位符URL (Uniform ResourceLocator)来查找目标网页,将用户所关注的数据内容直接返回给用户,并不需要用户以浏览网页的形式去获取信息,为用户节省了时间和精力,并提高了数据采集的准确度,使用户在海量数据中游刃有余。网络爬虫的最终目的就是从网页中获取自己所需的信息。虽然利用urllib、urllib2、re等一些爬虫基本库可以开发一个爬虫程序,获取到所需的内容,但是所有的爬虫程序都以这种方式进行编写,工作量未免太大了些,所有才有了爬虫框架。使用爬虫框架可以大大提高效率,缩短开发时间。
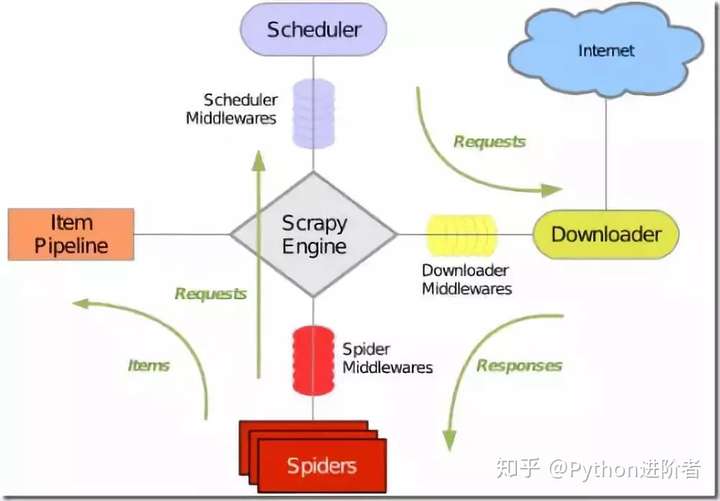
网络爬虫(web crawler)又称为网络蜘蛛(web spider)或网络机器人(web robot),另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或蠕虫,同时它也是“物联网”概念的核心之一。网络爬虫本质上是一段计算机程序或脚本,其按照一定的逻辑和算法规则自动地抓取和下载万维网的网页,是搜索引擎的一个重要组成部分。

网络爬虫一般是根据预先设定的一个或若干个初始网页的URL开始,然后按照一定的规则爬取网页,获取初始网页上的URL列表,之后每当抓取一个网页时,爬虫会提取该网页新的URL并放入到未爬取的队列中去,然后循环的从未爬取的队列中取出一个URL再次进行新一轮的爬取,不断的重复上述过程,直到队列中的URL抓取完毕或者达到其他的既定条件,爬虫才会结束。具体流程如下图所示。

随着互联网信息的与日俱增,利用网络爬虫工具来获取所需信息必有用武之地。使用网络爬虫来采集信息,不仅可以实现对web上信息的高效、准确、自动的获取,还利于公司或者研究人员等对采集到的数据进行后续的挖掘分析。

另外有需要云服务器可以了解下创新互联cdcxhl.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。